이번 회차에서는 기본적인 sql 쿼리까지도 자동으로 처리해주는 편리한 JPA를 배운다.
ORM(Object-Relational Mapping)이란?
JPA는 ORM을 한다.
ORM은 자바의 객체와 관계형 데이터베이스의 데이터를 서로 짝지어주는 것을 의미한다.
자바에서 다루는 것은 객체에 담긴 필드와 메소드이고 관계형 데이터베이스가 다루는 것은 테이블에 담긴 데이터다.
그러므로 개발자의 입장에서 서로 맞물려 돌아가야 하는 양쪽의 요소들 사이에 차이가 발생한다.
원래는 자바 따로, 관계형 데이터베이스 따로 직접 관리해서 잘 어울려 작동하게 해주어야 한다.
그 작업을 대신 해주는 것이 ORM이다.
ORM 덕분에, 개발자는 객체만을 사용하여 관계형 데이터베이스를 간접적으로 다룰 수 있다.
ORM이 만능인 것은 아니다. 프로젝트의 크기가 커질수록 ORM을 설계하는 난이도가 높아지고, ORM만으로 다 해결할 수가 없어 직접 데이터베이스를 다루어야 하는 부분이 생긴다고 한다.
그러나 ORM의 의의는 매우 크다.
데이터베이스와 관련된 문제들을 덜 신경쓰는 대신,
그 대신 비즈니스 로직에 더 중점을 두며, 더 객체지향적으로 프로그램을 짤 수 있다.
라이브러리 및 환경 설정
지금 이 글이 두 번이나 날아가서 열받으니깐 대충 적겠다.

build.gradle에서 jdbc 관련 라이브러리를 지우고 data-jpa를 넣는다.
적었으면 오른쪽 위에 표시될 코끼리 새로고침(gradle refresh)도 잊지 말고 눌러준다.
data-jpa는 jdbc와 jpa를 모두 포함한다고 한다.

다음은 application.properties이다.
4번째 줄부터 5번째 줄까지가 이번에 추가하는 부분이다.
4번째 줄의 show-sql을 true로 설정하면 jpa가 만들어내는 sql문을 우리가 볼 수 있게 된다.
5번째 줄의 ddl-auto를 create로 설정하면 jpa가 테이블을 자동으로 새로 생성한다. 그러나 우리는 member라는 테이블을 이미 만들어놓고, 프로그램은 그 테이블에 데이터를 넣고 빼고 수정하는 일만 할 것이다. 따라서 이건 none으로 설정해준다.
엔티티 설정
ORM이 작동하려면, 자바 코드 내의 어떤 놈이 매핑의 대상이 될 것인지
즉 어떤 놈이 JPA가 관리하는 엔티티가 될 것인지를 지정해주어야 한다.
어노테이션을 붙여 지정하면 된다.
우리가 테이블에 집어넣을 대상은 Member 객체이므로, domain의 Member 클래스로 가서 어노테이션을 붙인다.
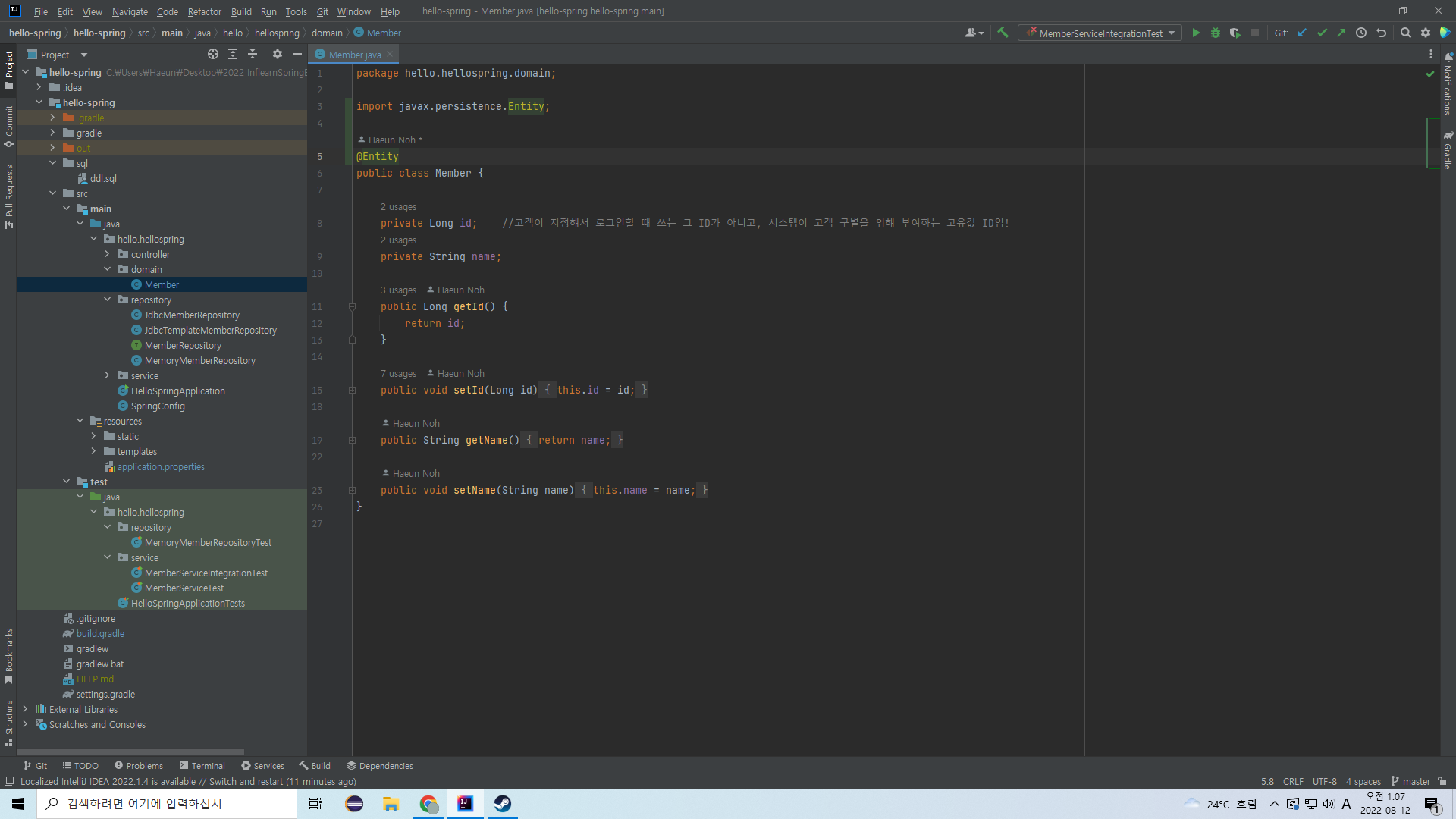
이렇게 @Entity를 붙여주면 JPA가 Member 객체를 엔티티로 인식하여 관리하고 데이터베이스와 매핑할 것이다.
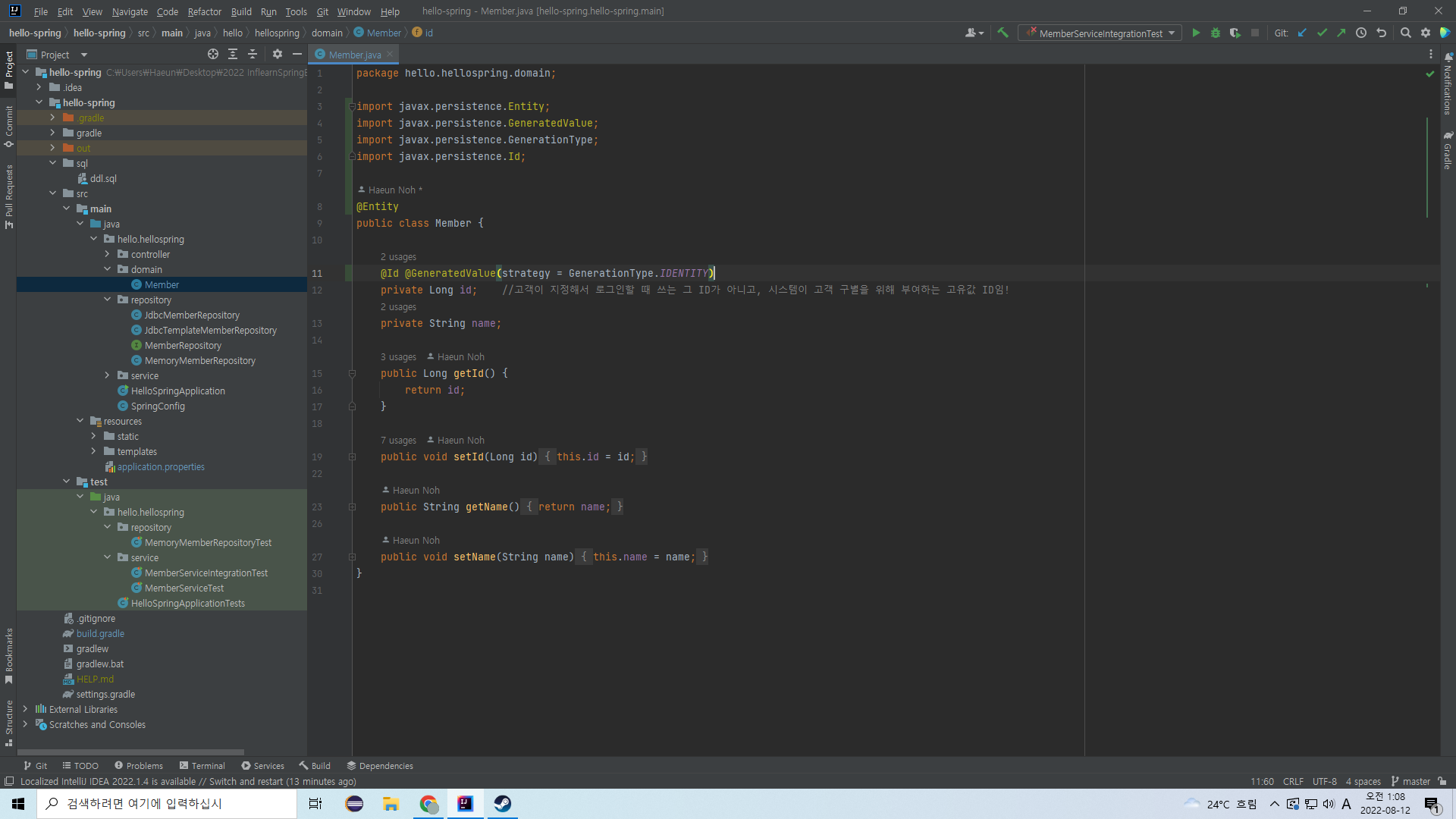
id 필드에는 이런 어노테이션들을 붙여준다.

@Id 어노테이션은 이 값이 각 데이터를 구분하는 고유값의 역할을 한다는 표시이다.
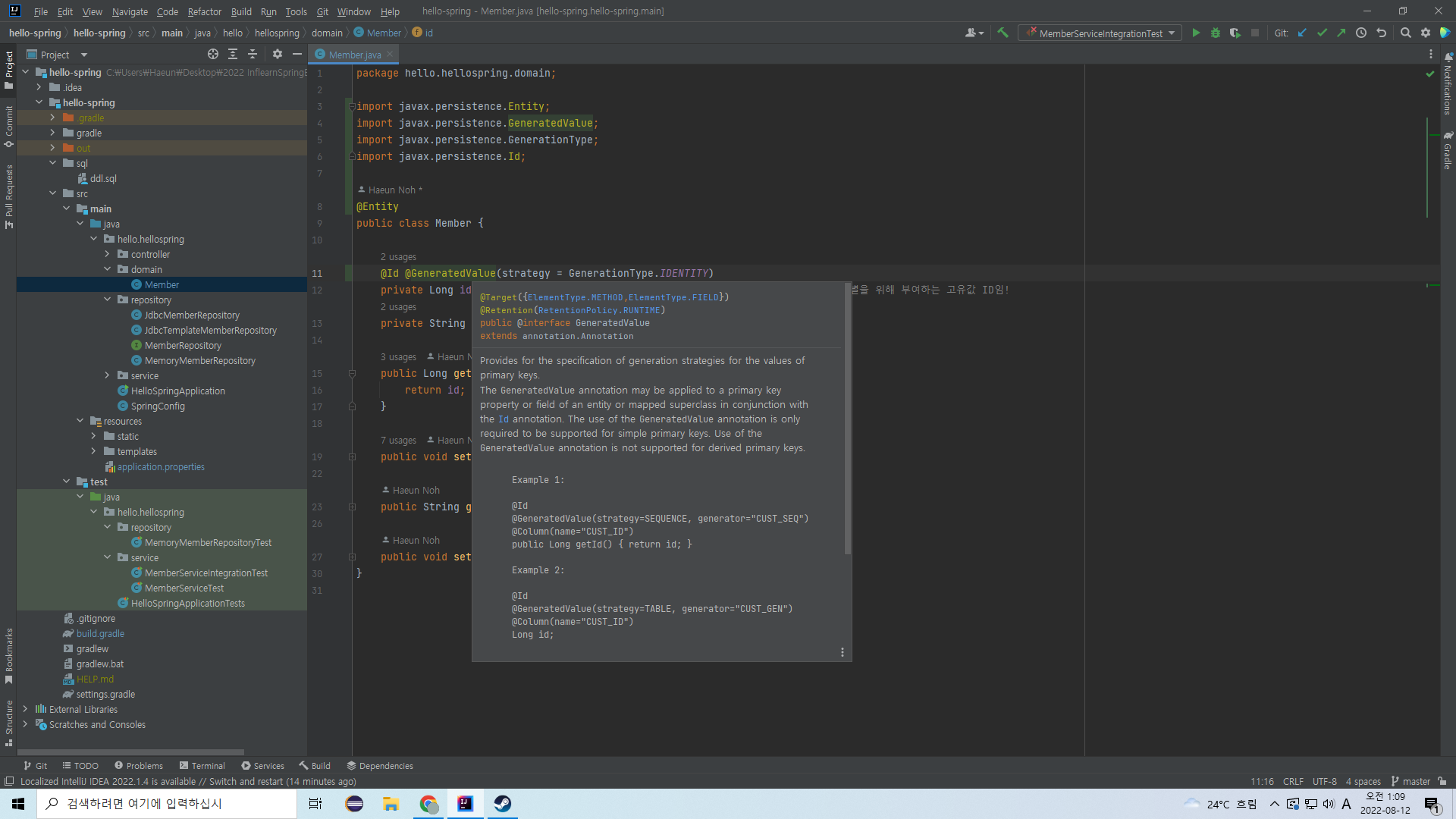
@GeneratedValue 어노테이션은 이 값이 지정되지 않았을 경우 자동으로 생성되도록 하게 만든다.
우리가 지금까지 계속 id는 지정되지 않을 경우 고유한 정수 값으로 생성되어 데이터베이스에 저장되도록 하지 않았는가? 그거다.
name에는 별다른 어노테이션을 붙여주지 않아도 되는데,
그 이유는 우리가 자바에서 정의한 필드의 이름 "name"과 테이블에 설정되어있는 컬럼의 이름 "name"이 동일하기 때문이다.
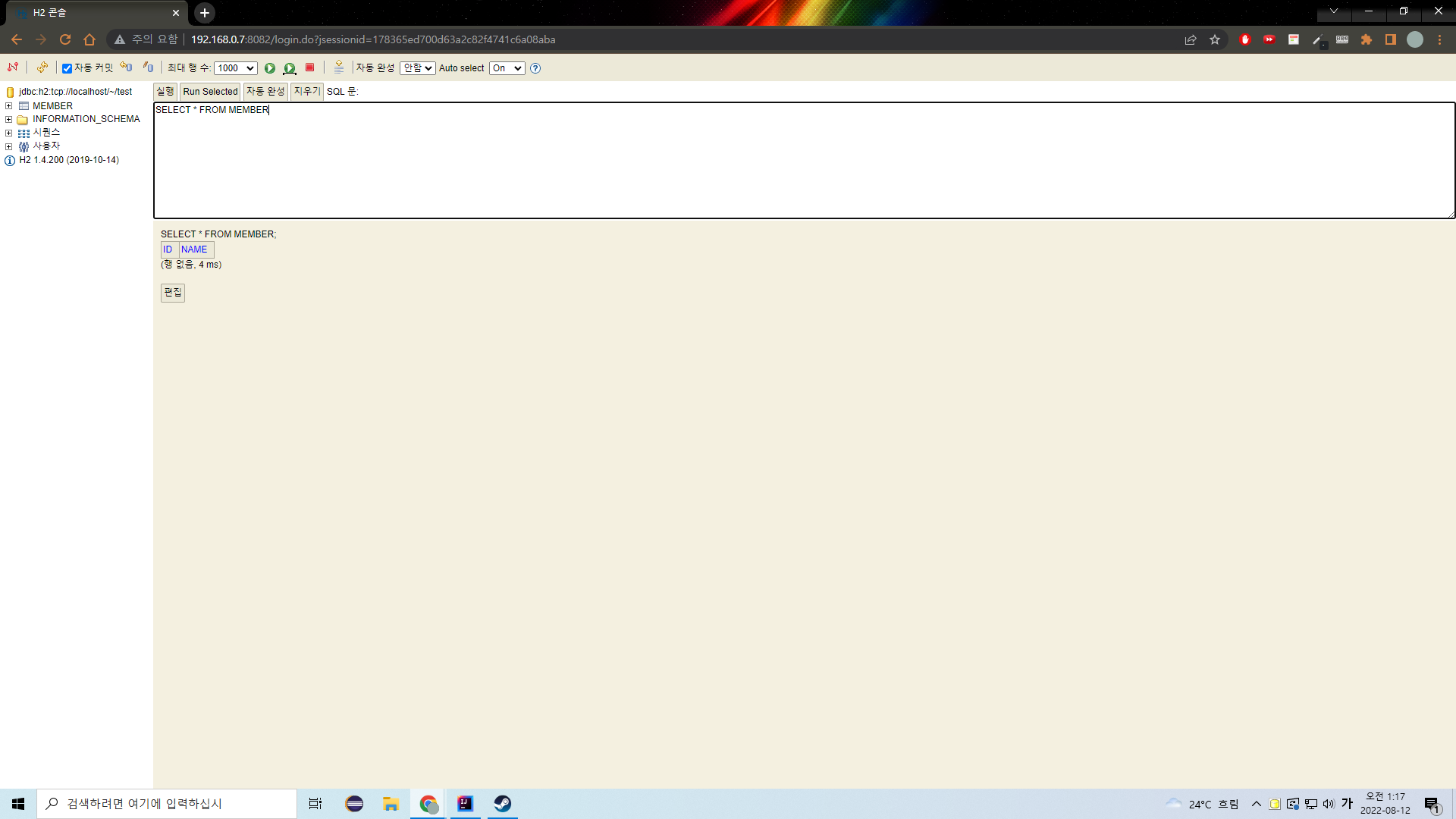
컬럼명이 id와 name이다.
그렇다면
필드와 매핑하고 싶은 컬럼의 이름이 서로 다를 때는 어떻게 해야 할까?
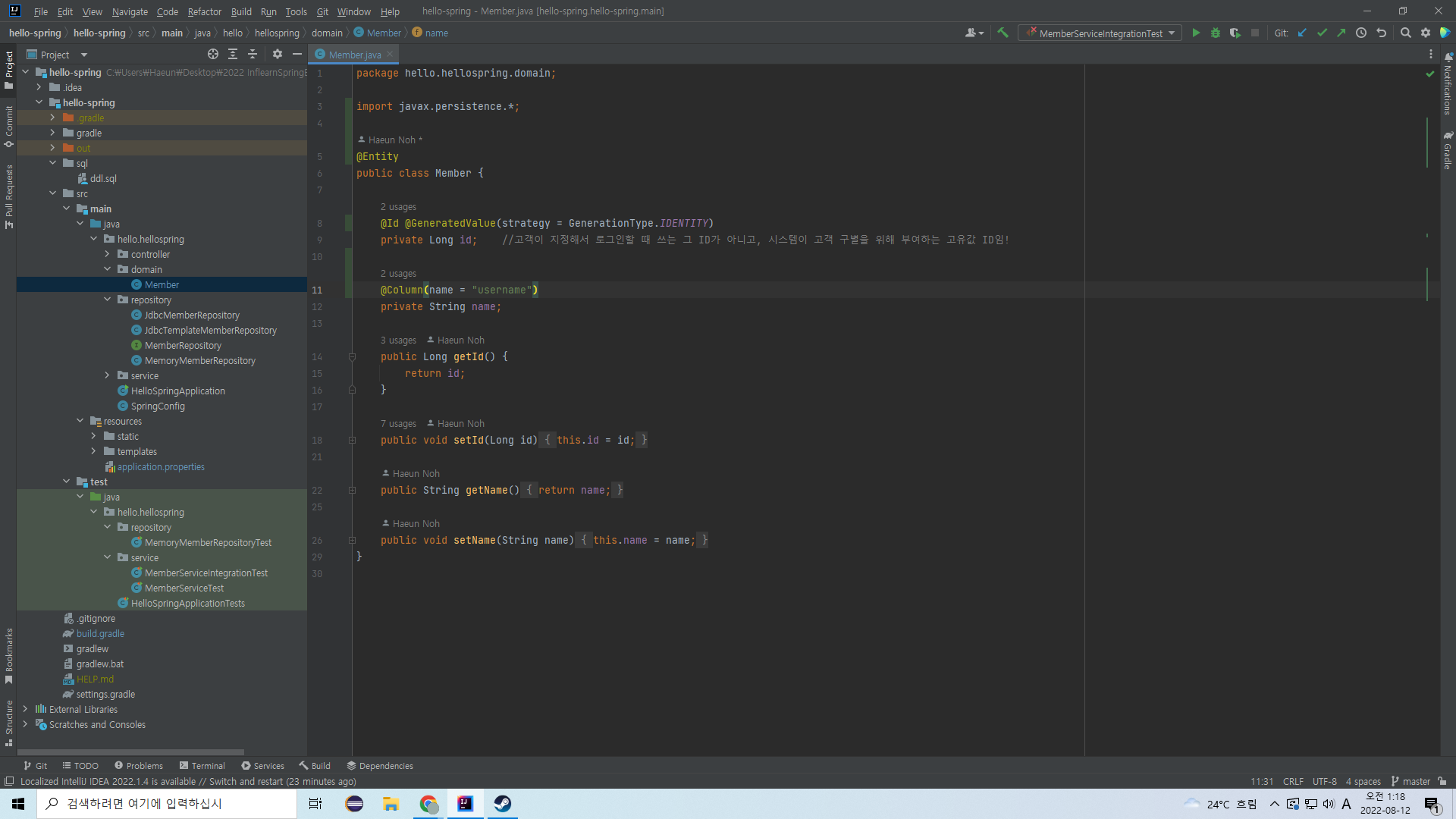
이렇게 @Column 어노테이션을 쓰면 된다.
괄호 안에는 이 필드와 매핑될 컬럼의 이름을 적어넣는다. 위의 경우에는 name 필드가 username이라는 컬럼과 매핑된다.
아무튼 이제 JPA는 이 어노테이션들이 제공하는 정보를 바탕으로 insert, delete 등의 sql문을 알아서 만들 수 있게 되었다.
리포지토리 만들기
이제 리포지토리를 만든다.
이렇게 준비를 해준다.
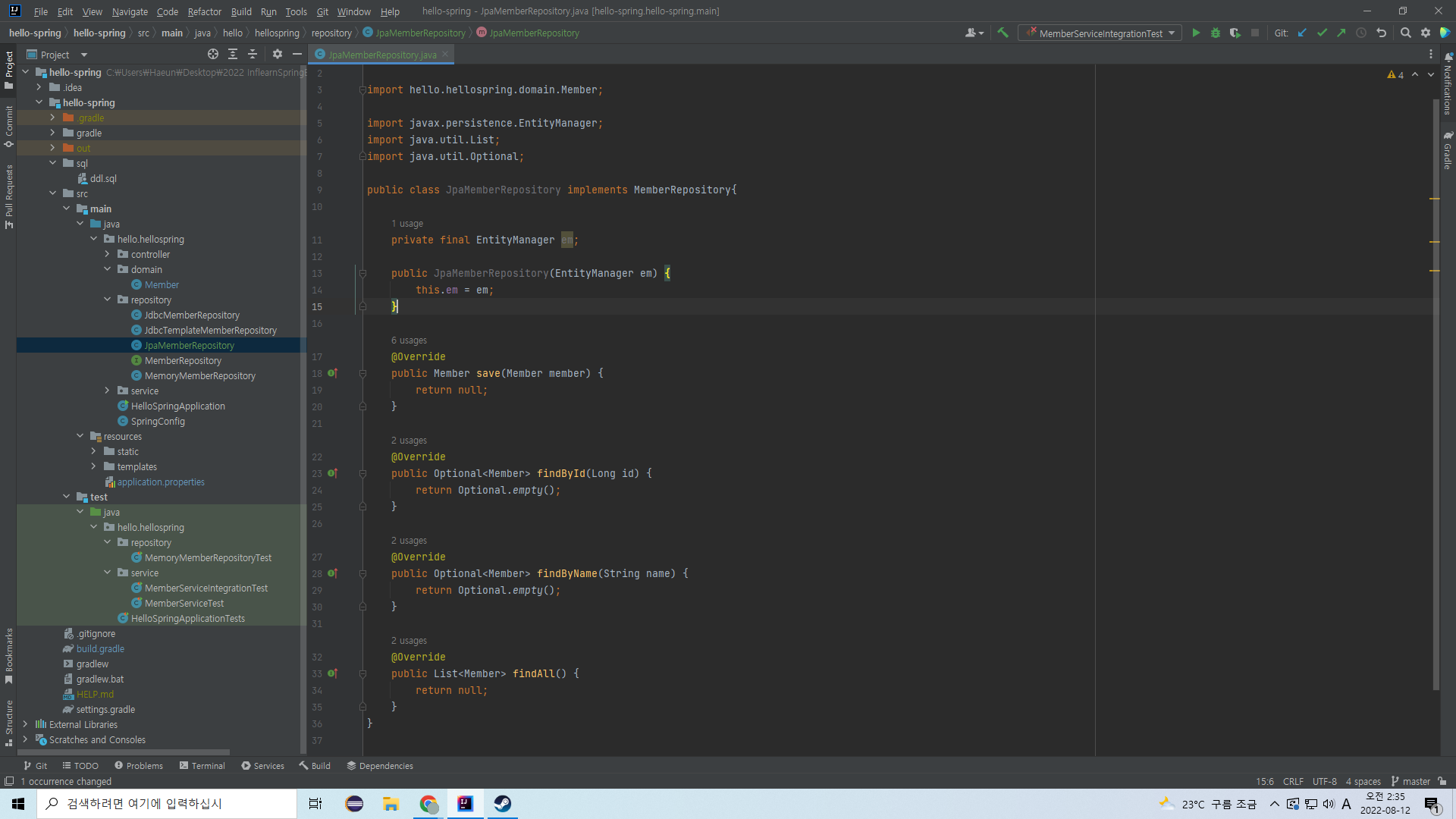
그리고 JPA의 동작에 꼭 필요한 EntityManager라는 것을 만들고, 생성자도 만들어준다.
이렇게 해주면
미리 마련해준 jpa 라이브러리, 환경설정, 지정한 엔티티에 대한 정보를 종합하여
스프링 부트는 EntityManager라는 도우미를 만들어준다.
만들어준 EntityManager를 위와 같은 생성자를 통해 주입받기만 하면 된다.
JPA에서는 이 EntityManger가 우리를 위해서 일한다.
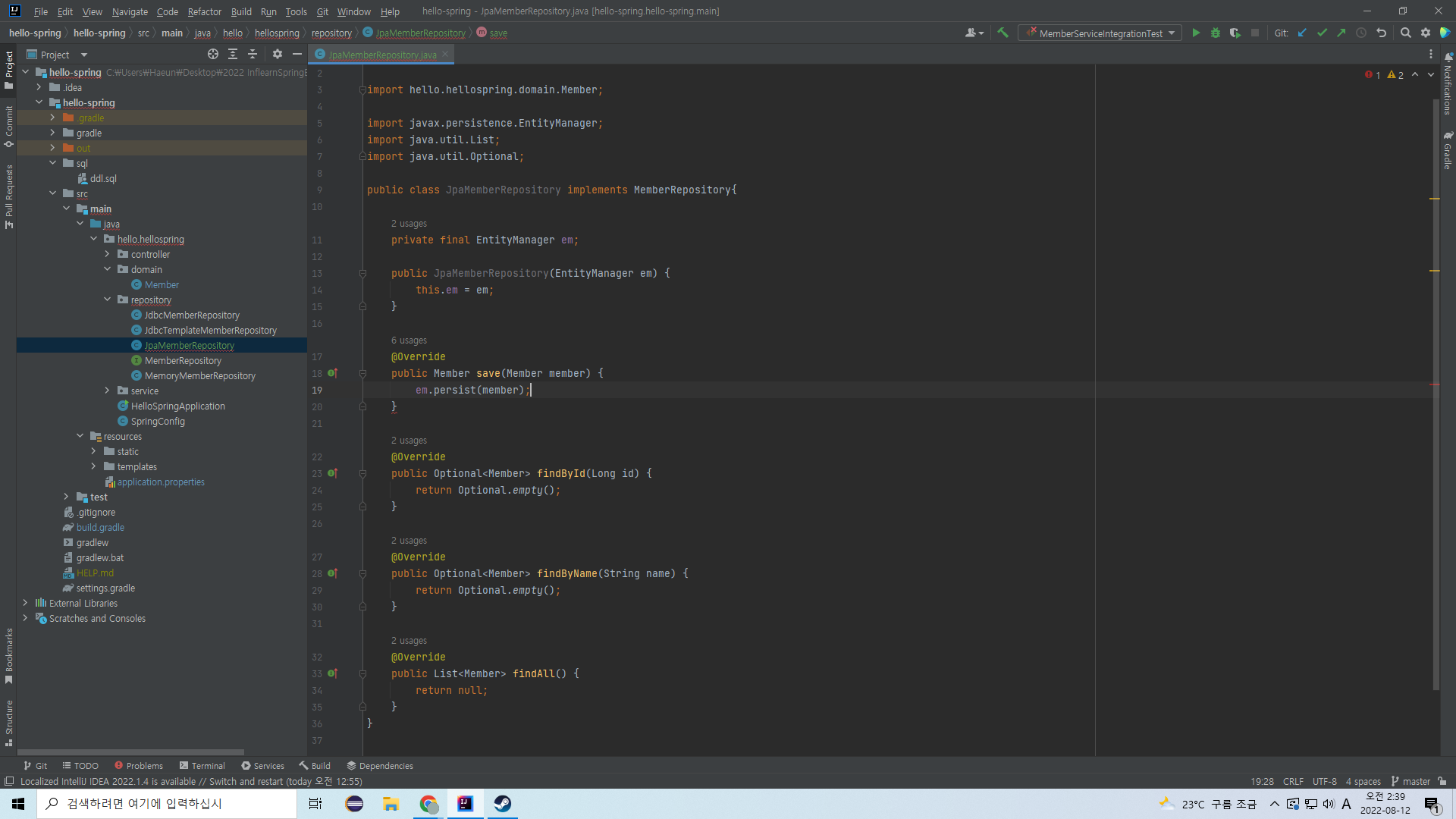
save(새 회원 정보 저장)은 사실 19번째 줄의 이 한 문장이면 끝난다. 매우 간편하다! id지정과 저장까지 한 번에 em이 해준다.
그러나 이것만 쓰면 안 된다. 우리는 객체지향 프로그래밍을 하고 있고, 이미 만들어놓은 다른 부품들에 이 리포지토리가 스무스하게 들어가도록 설계해야 한다.
그러므로 리턴 타입을 지금까지와 똑같이 맞추어주자.

이렇게 member를 리턴하면 된다.
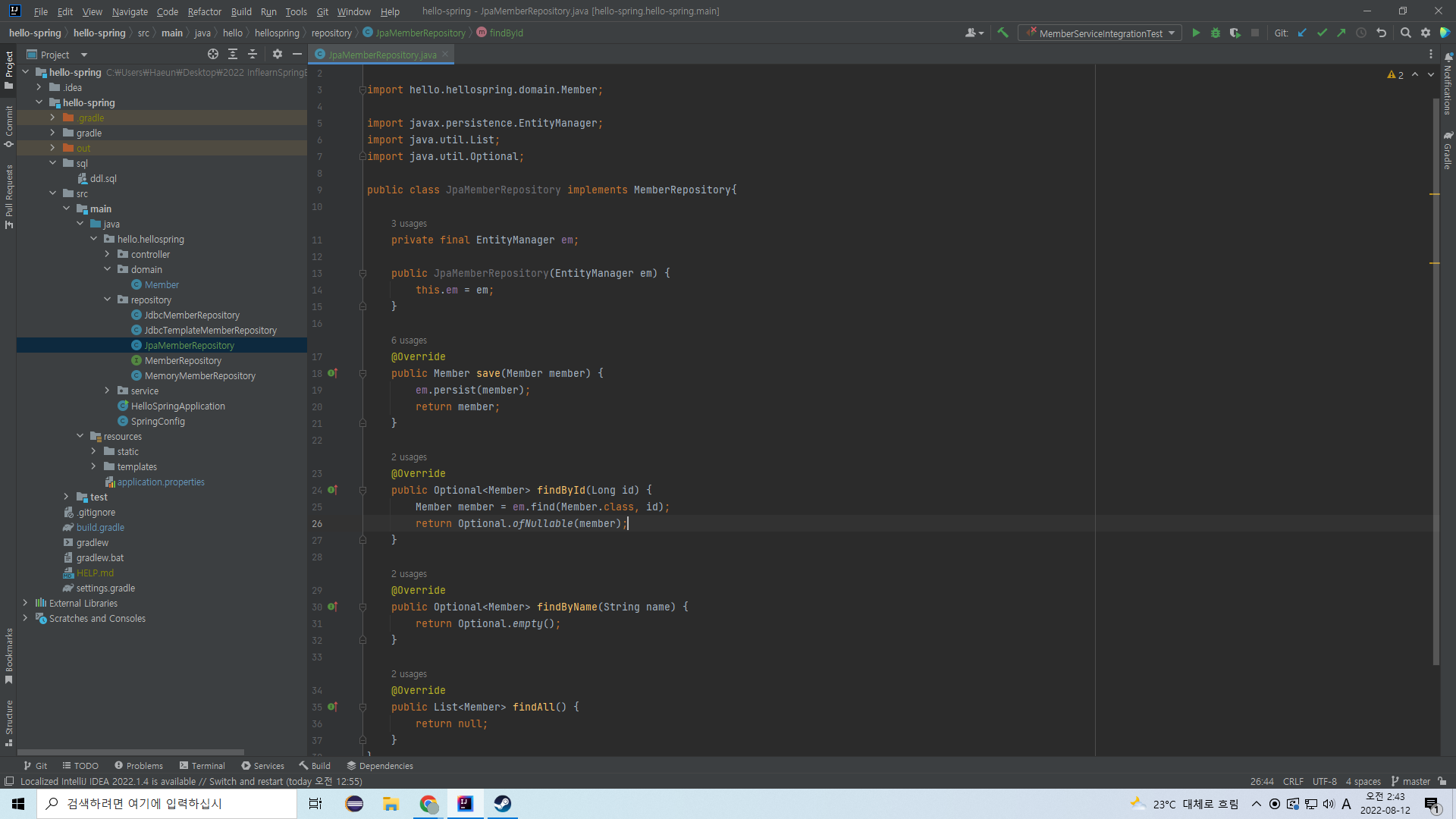
findById는 이렇게 해준다.
em.find()안에 Member 클래스에 대한 정보와 찾기의 기준인 id를 넣어준다.
member를 Optional에 싸서 리턴해준다.
.class가 낯설어서 아래 게시글에 간단하게 조사해두었다.
Class로 클래스의 정보 얻어오기 (리플렉션)
인프런에서 스프링 입문 강의를 듣다 보니 .class라는 것이 많이 나와서, 이것이 뭔지 간단하게 정리해두고자 한다. 리플렉션(1), Class 클래스 리플렉션(Reflection)은 객체를 통해 클래스의 정보를 분
blowupmomo.tistory.com
findById는 primary key(고유값)을 기준으로 객체를 찾아오는 것이기 때문에 위처럼 간단한 코드로 구현할 수 있다.
그러나 findByName과 findAll은 em.find()로 구현할 수 없다.
이 둘은 객체지향 쿼리인 JPQL을 사용하여 구현해야 한다.
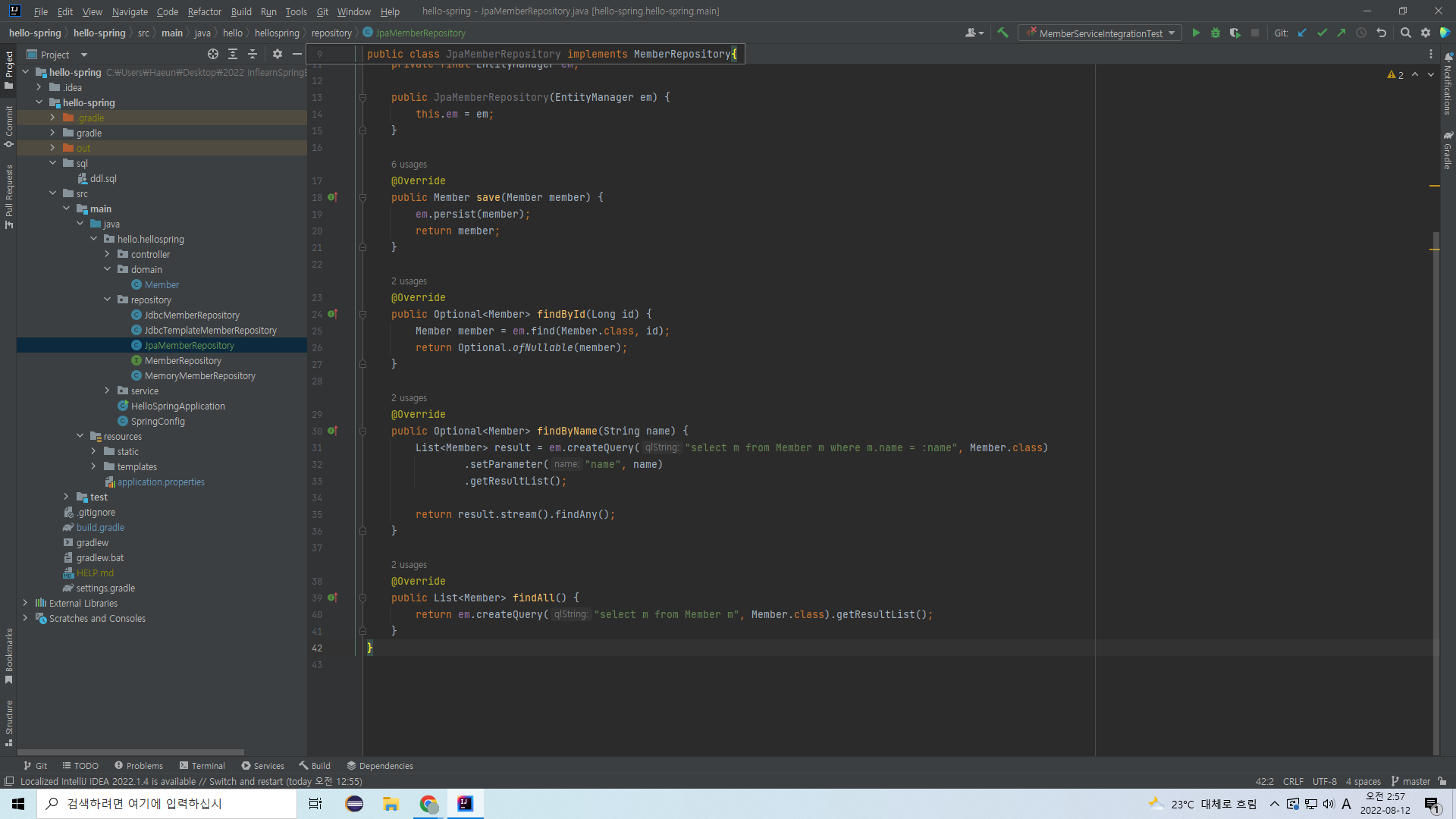
이렇게 해주면 된다.
JPQL의 문법 같은 것은 별도의 게시글을 만들어 정리하기로 하자.
간단히 이해하자면,
SQL이 데이터베이스의 테이블을 대상으로 쿼리를 날린다면
JPQL은 엔티티 객체를 대상으로 쿼리를 날린다.
findByName은 탐색 결과를 List로 받아온 다음 그 리스트의 스트림에 하나라도 결과물이 존재하는지 훑어서 Optional에 담아 리턴한다.
탐색 결과를 Member 객체로 받아와 그대로 리턴하지 않고
이렇게 List로 받아와 한 번의 과정을 더 거치는 것은
Optional을 리턴하기 위해서이다.
findAll은 탐색 결과를 List로 받아와 그대로 리턴한다.
다음 시간에 배울 스프링 데이터 JPA를 사용하면 JPQL조차 안 짜도 된다.
Transaction 설정
JPA를 사용할 때 주의할 점이 있다!
데이터베이스에 데이터를 넣는 작업은 반드시 transaction 내부에서 이루어져야 한다.
그러므로 Service 코드에 다음과 같이 어노테이션을 붙여준다.
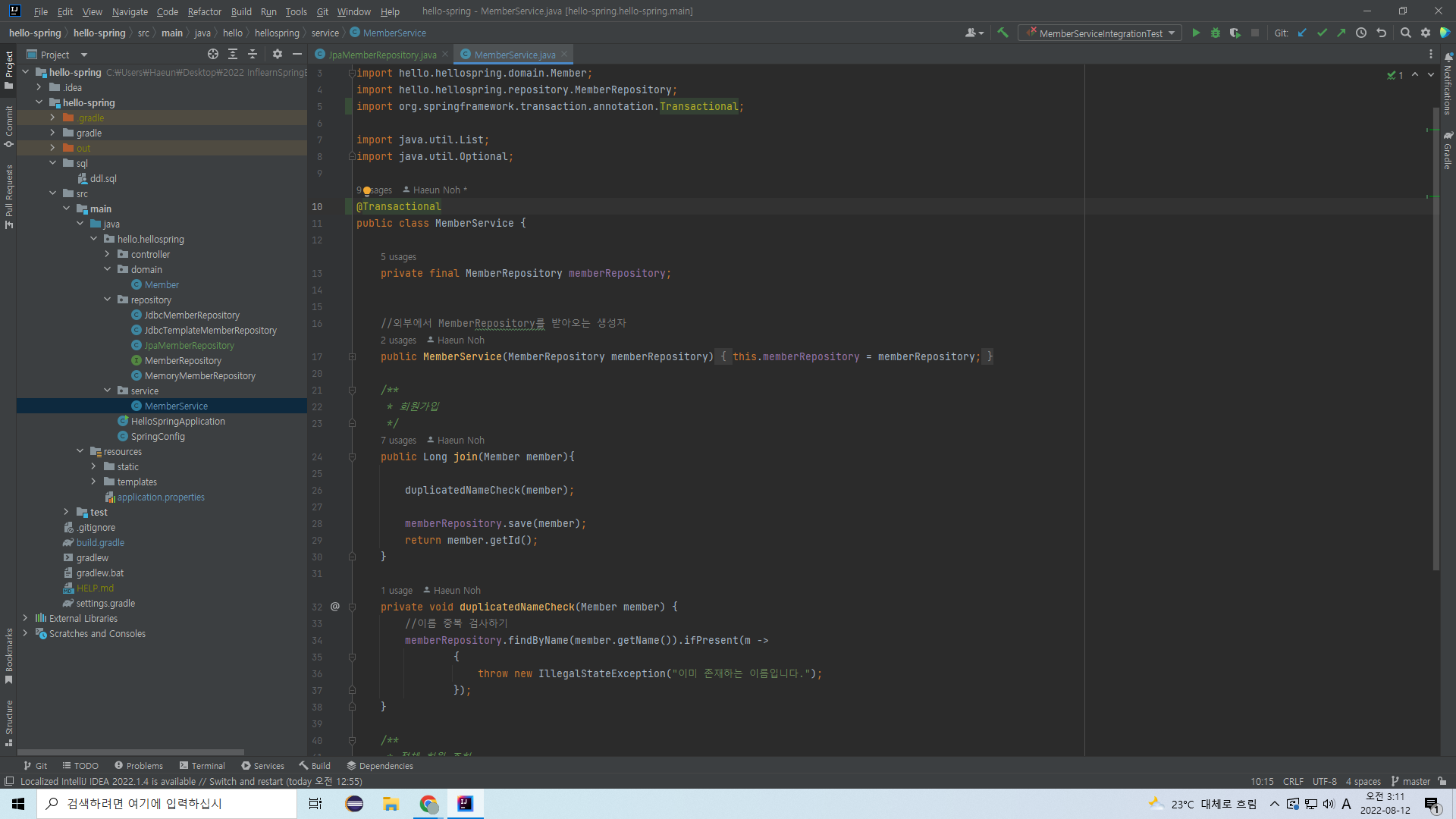
사실은 join에서만 데이터 삽입이 일어나므로 join에 붙여도 되지만 그냥 여기에 붙이시겠다고 한다.
Configuration 설정
리포지토리를 갈아끼우자.
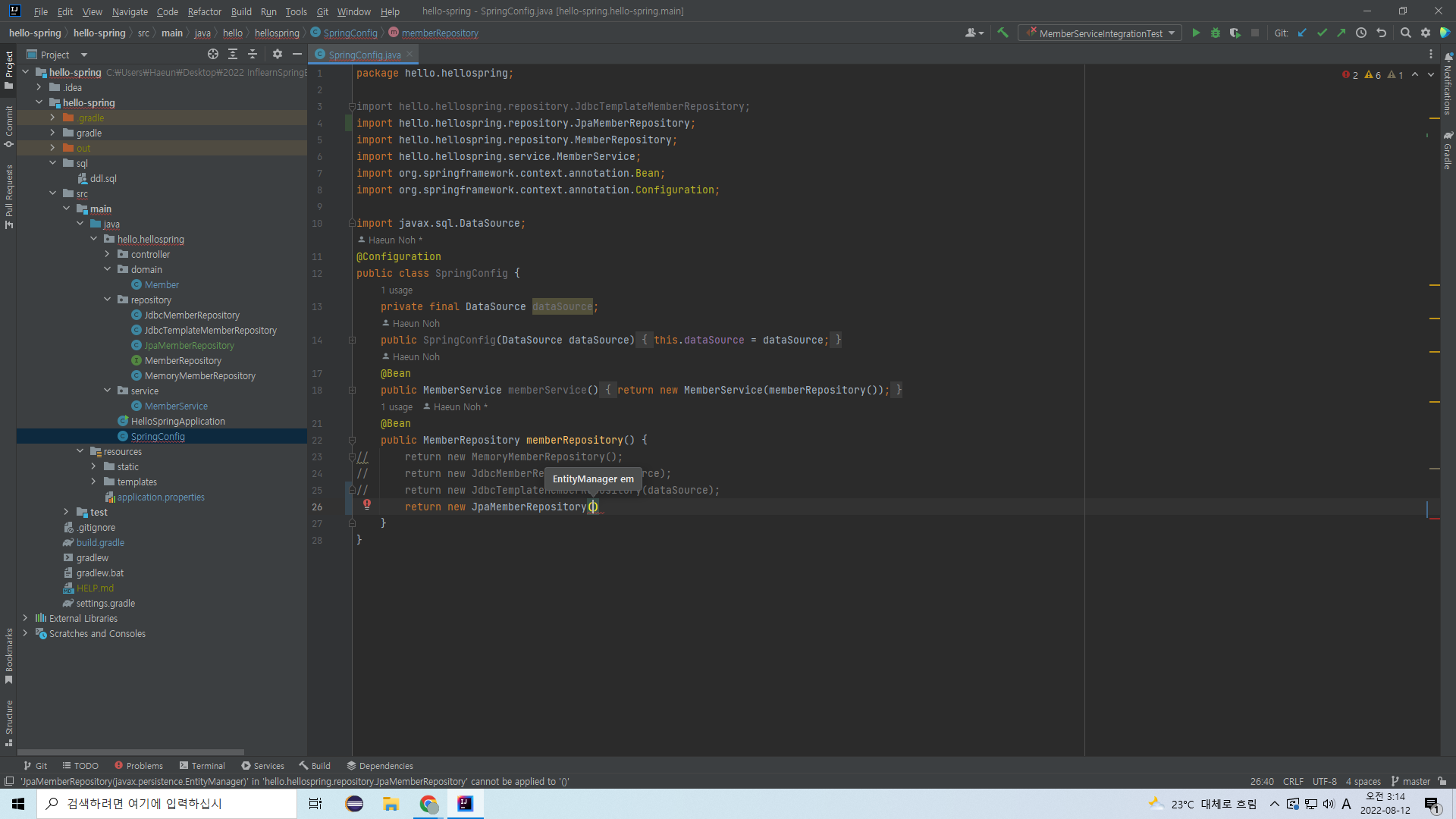
엔티티매니저를 넣어달란다.
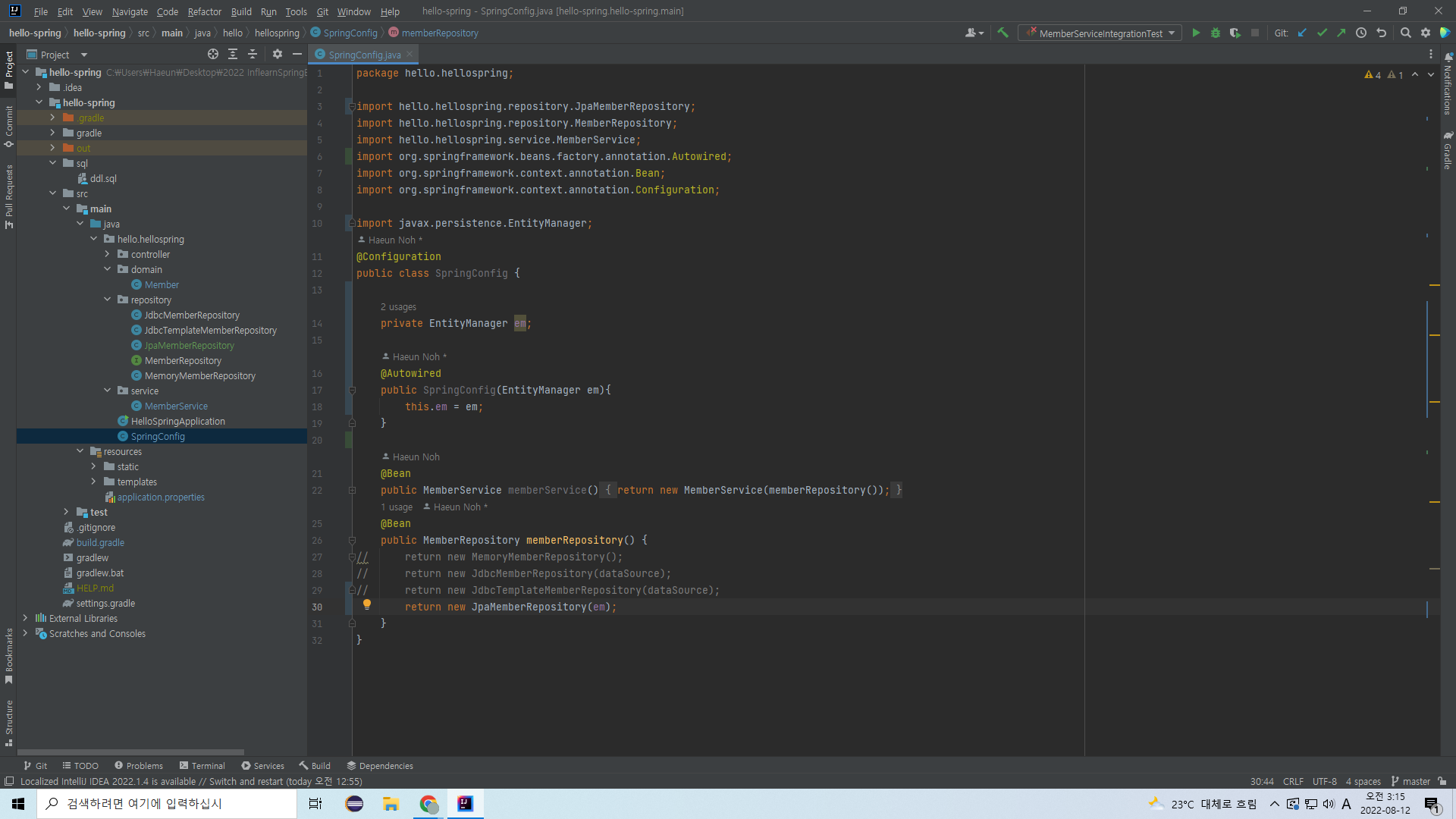
이제 DataSource는 필요 없으니, DataSource 관련 필드와 생성자를 지우고 EntityManager를 주입받는 것으로 바꾼다.
주입받은 EntityManager를 JpaMemberRepository의 생성자 매개변수로 넣어준다.
테스트하기
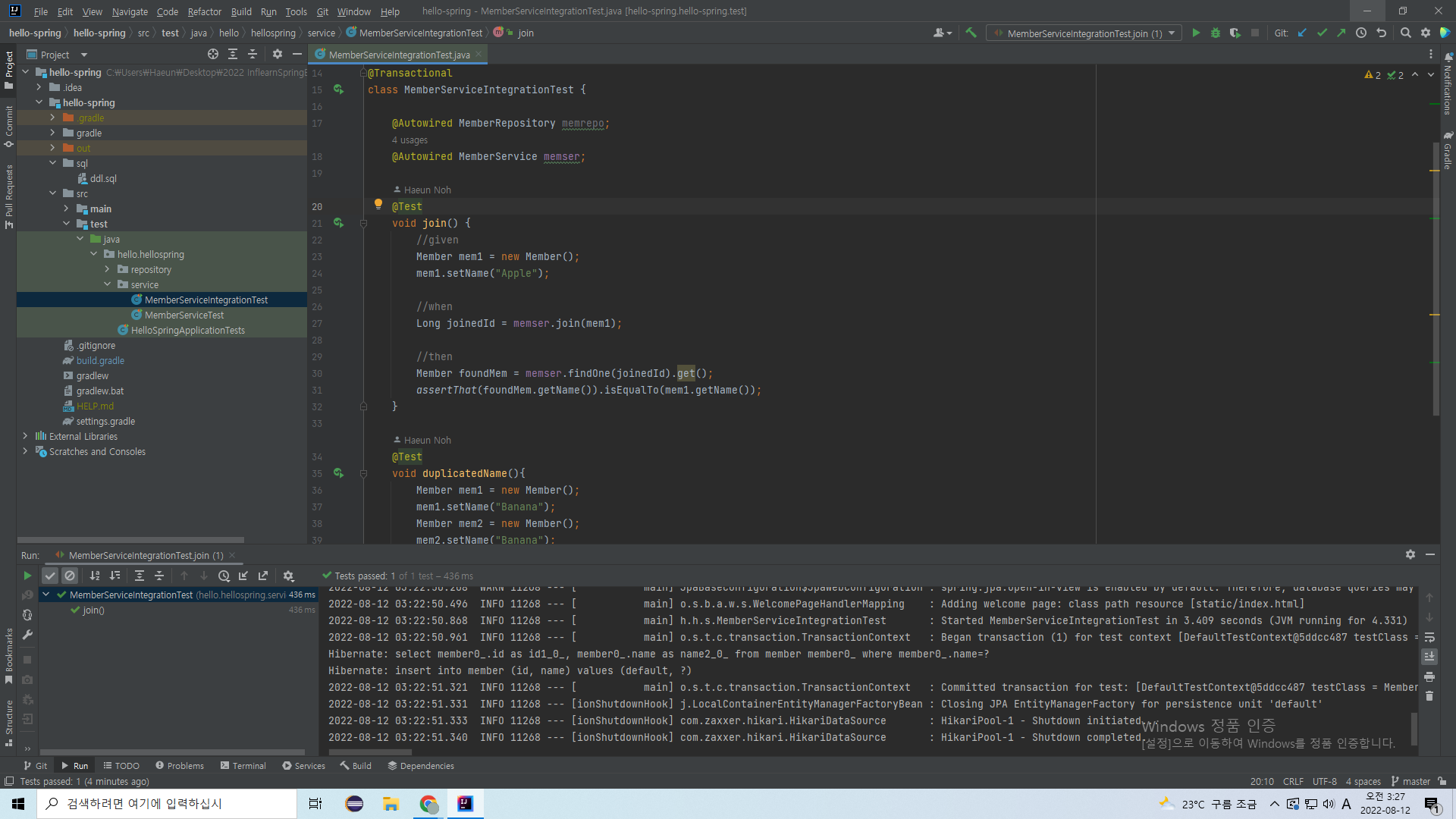
통합 service 테스트를 수정 없이 돌리면 된다.
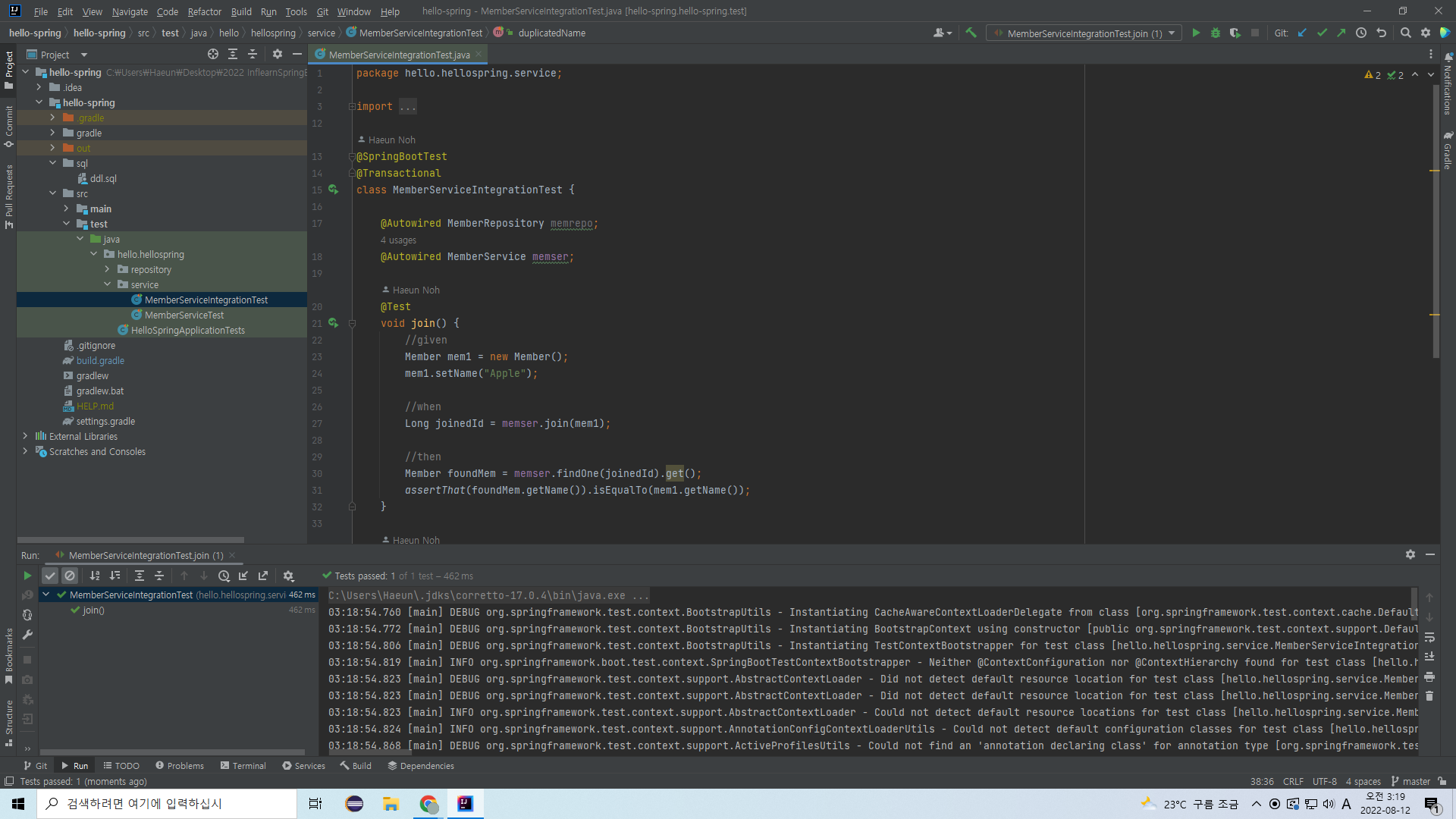
강사님처럼 일단 join만 돌려봤다. 잘 pass되었다.
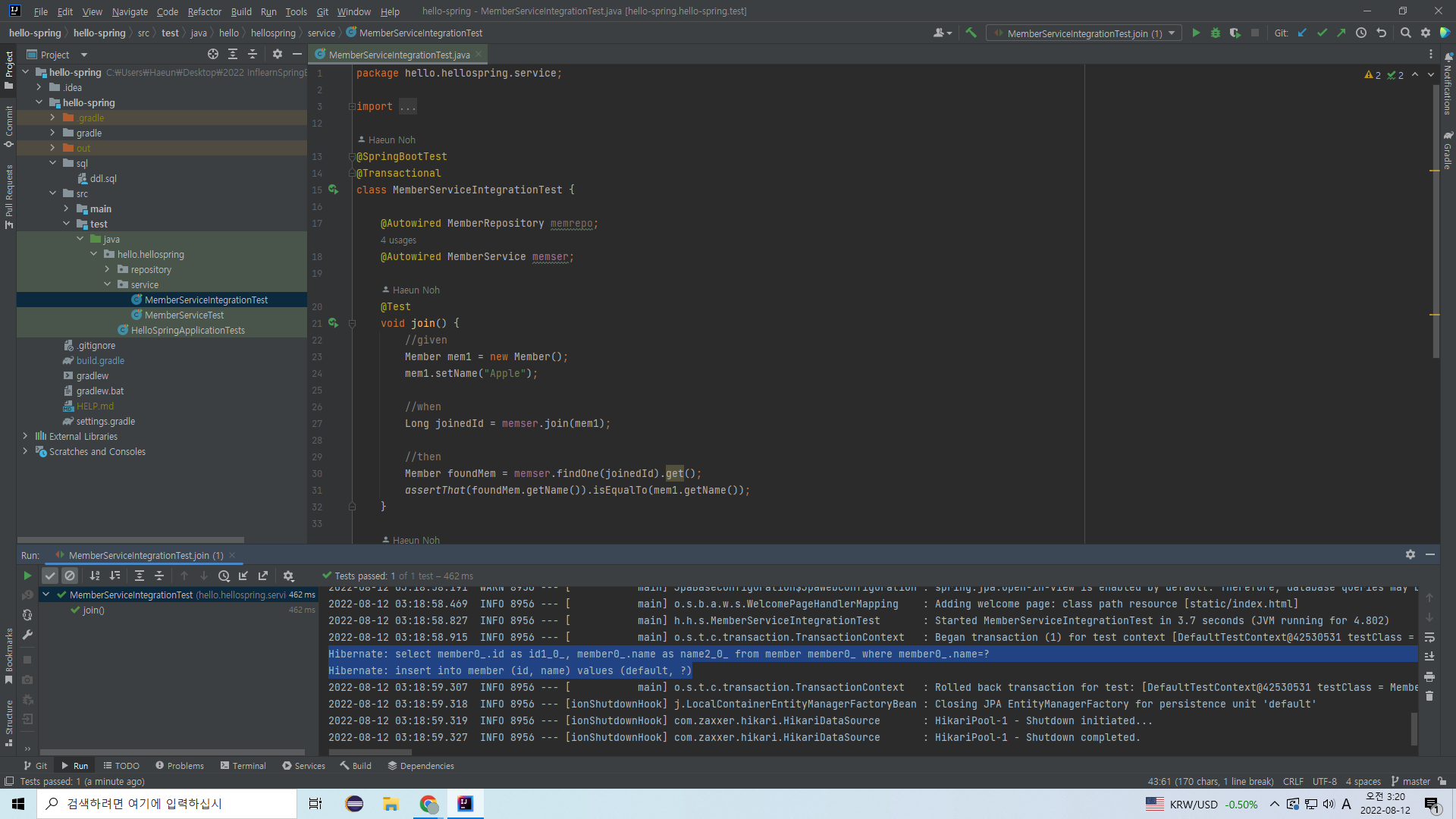
여기를 보면 JPA가 만들어준 SQL 쿼리가 보인다.
위의 것은 assert를 위해 데이터를 찾아오는 문장, 아래 것은 데이터를 삽입하는 문장이다.
@Commit을 붙여서 실제 데이터베이스에 잘 들어가는지도 살펴보자.
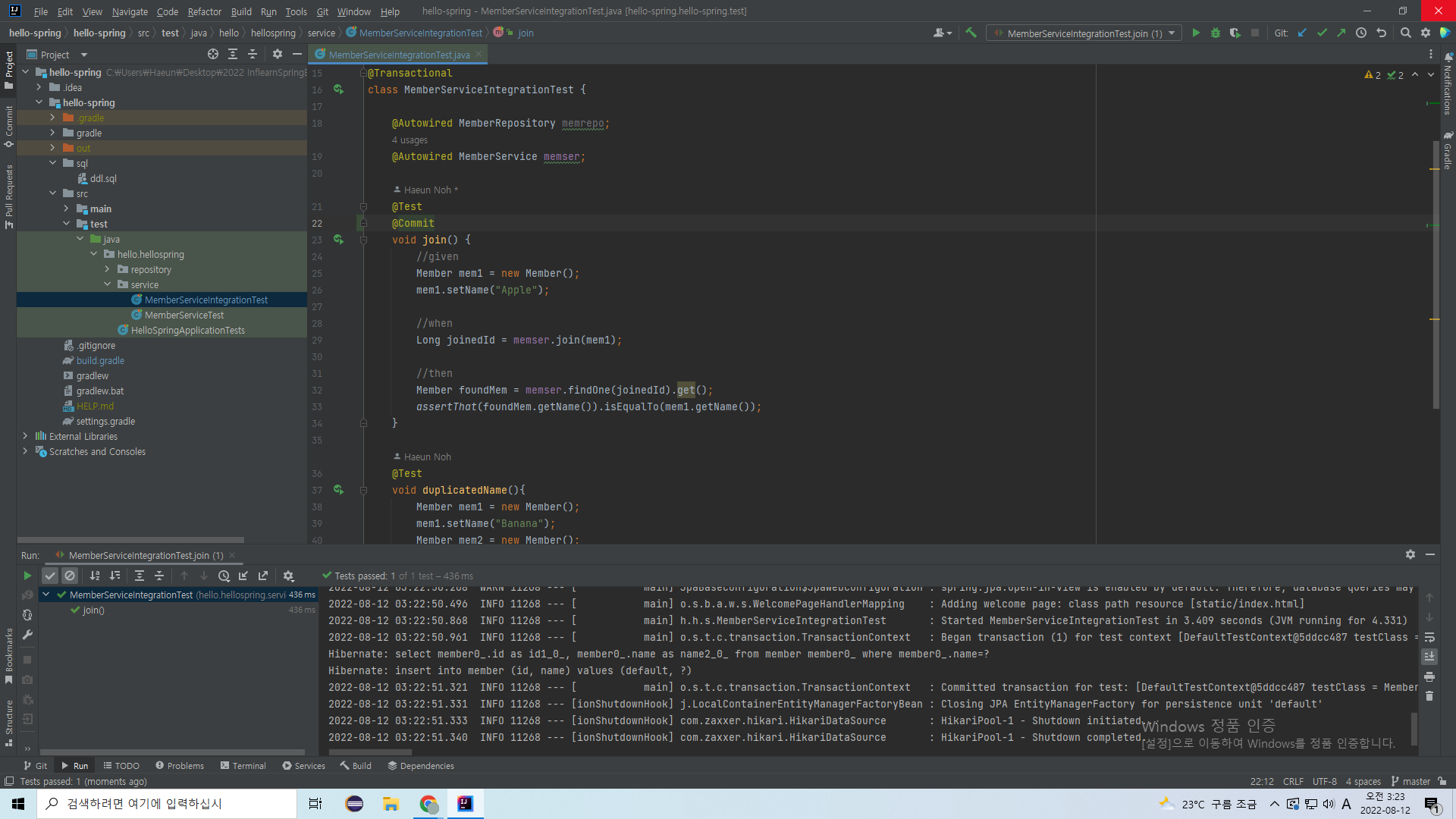
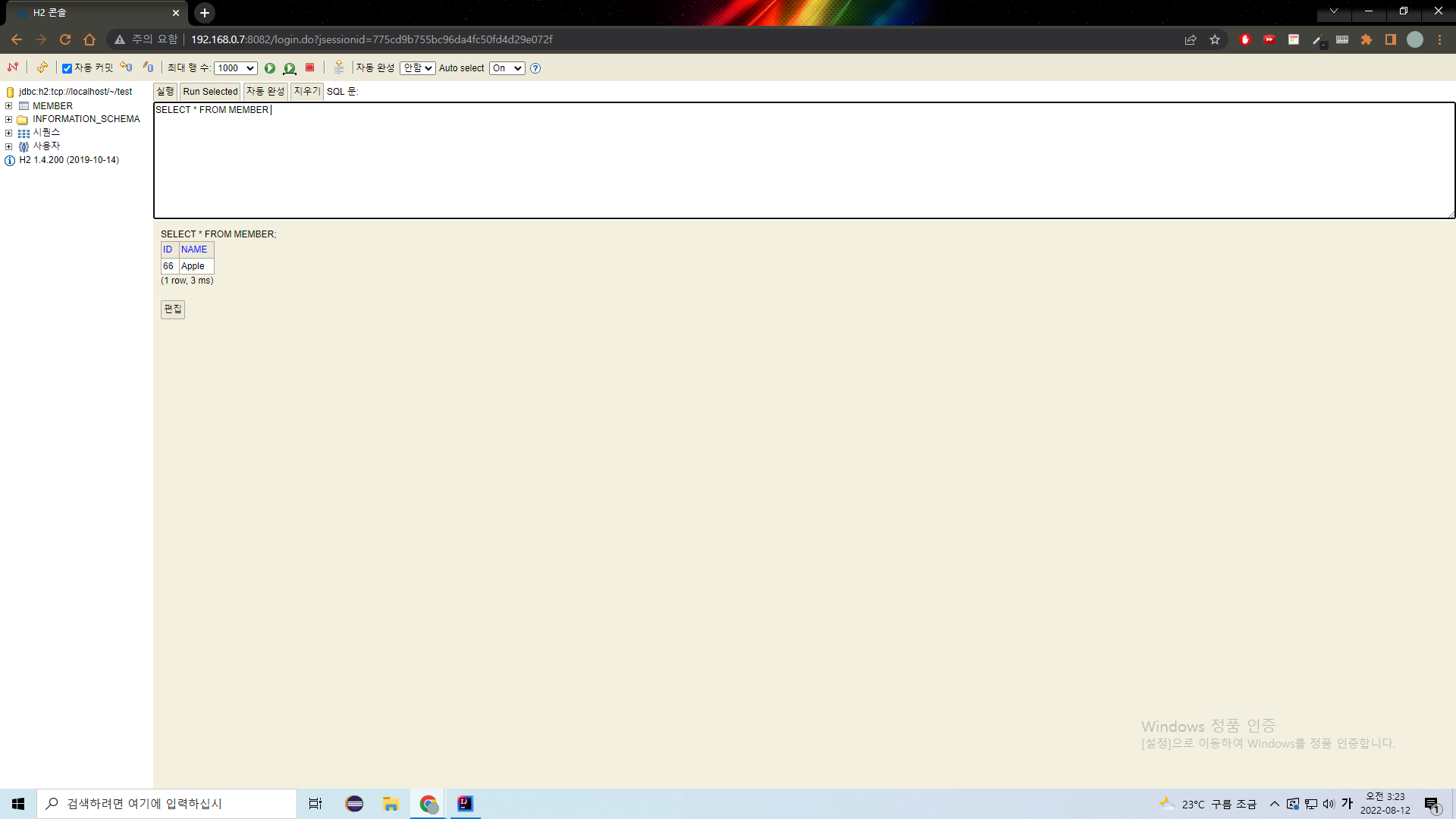
이름이 Apple인 회원 정보가 잘 들어갔다.
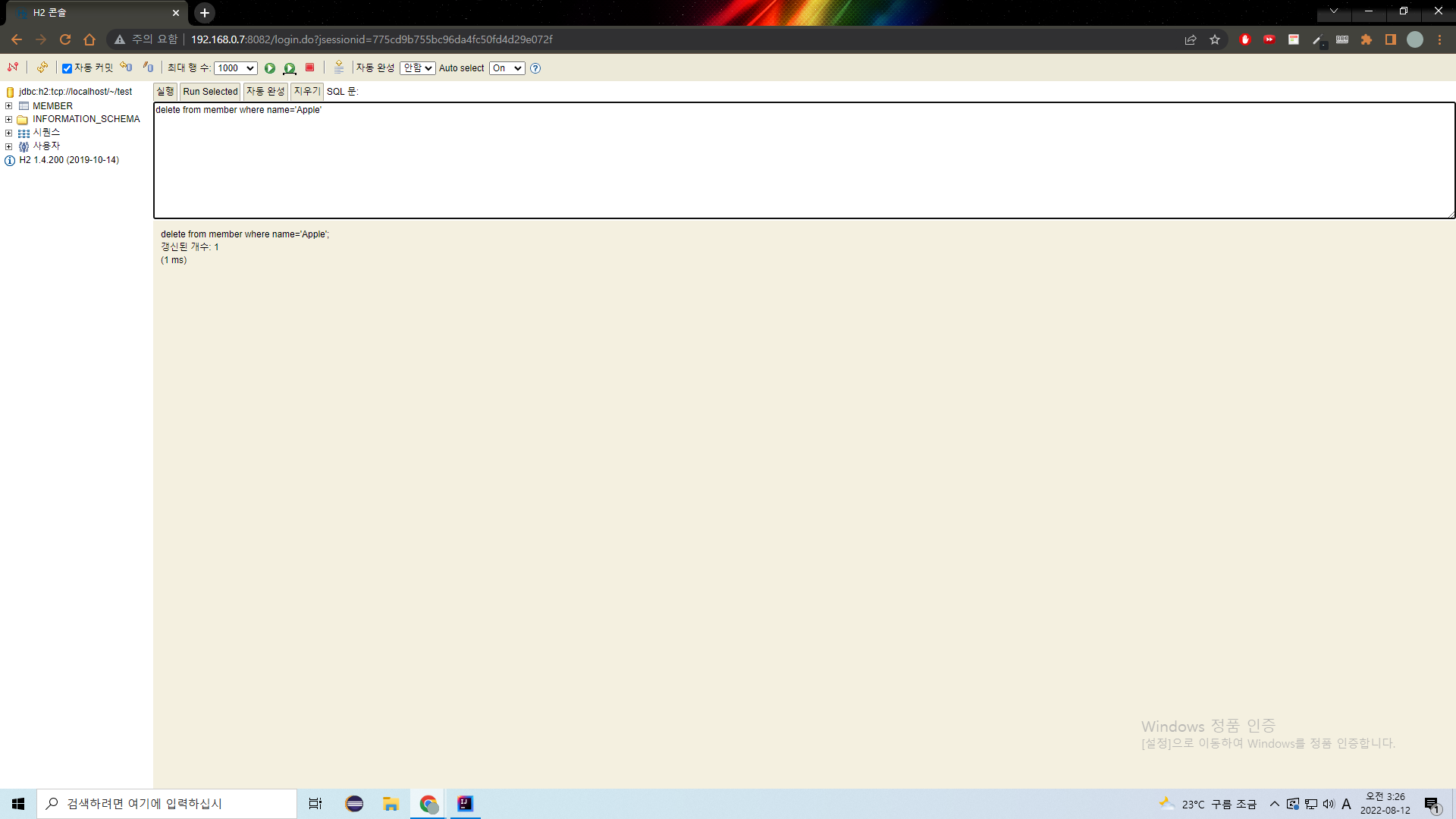
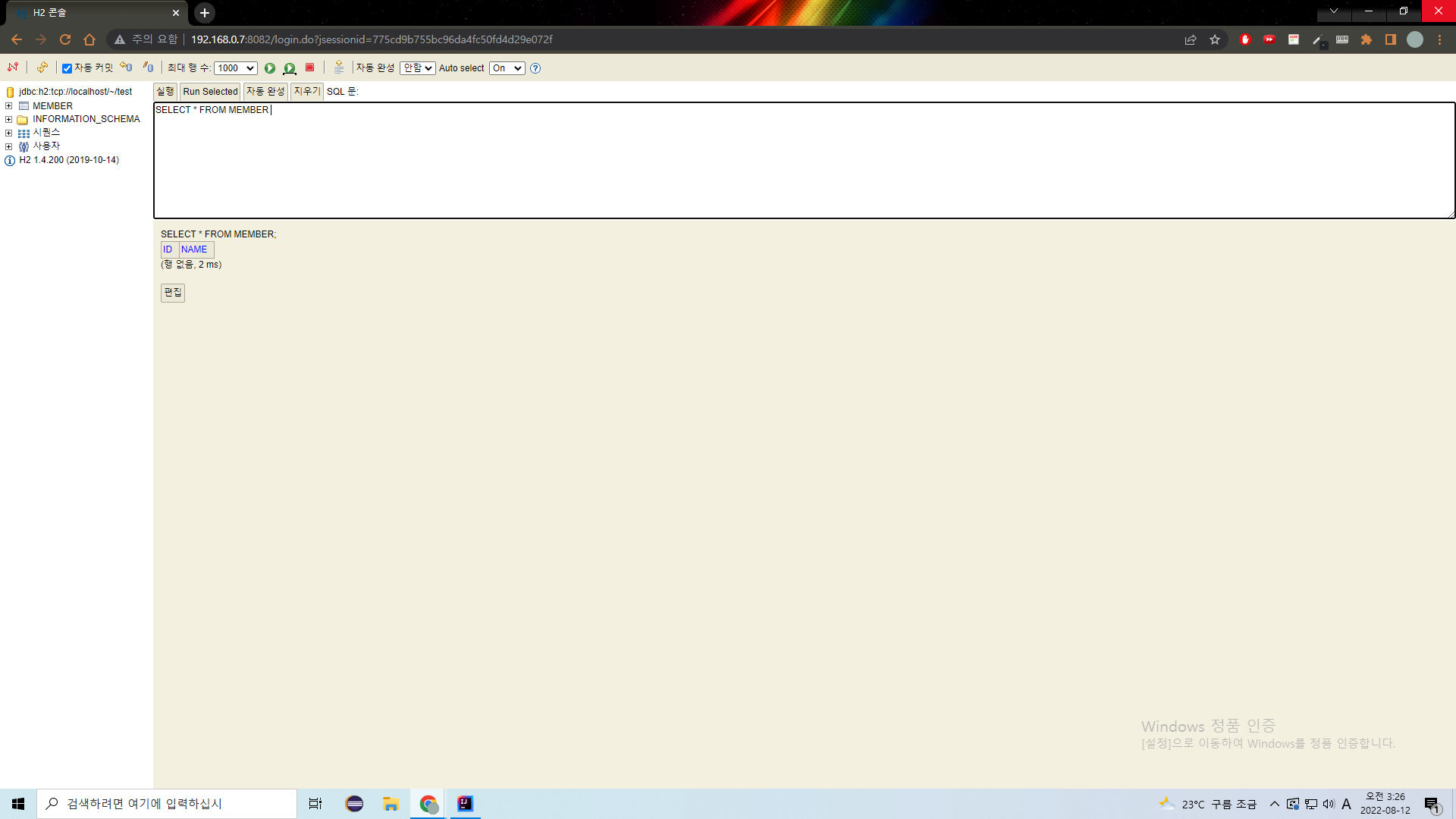
확인했으니 다시 지워주자.
@Commit도 지우자.
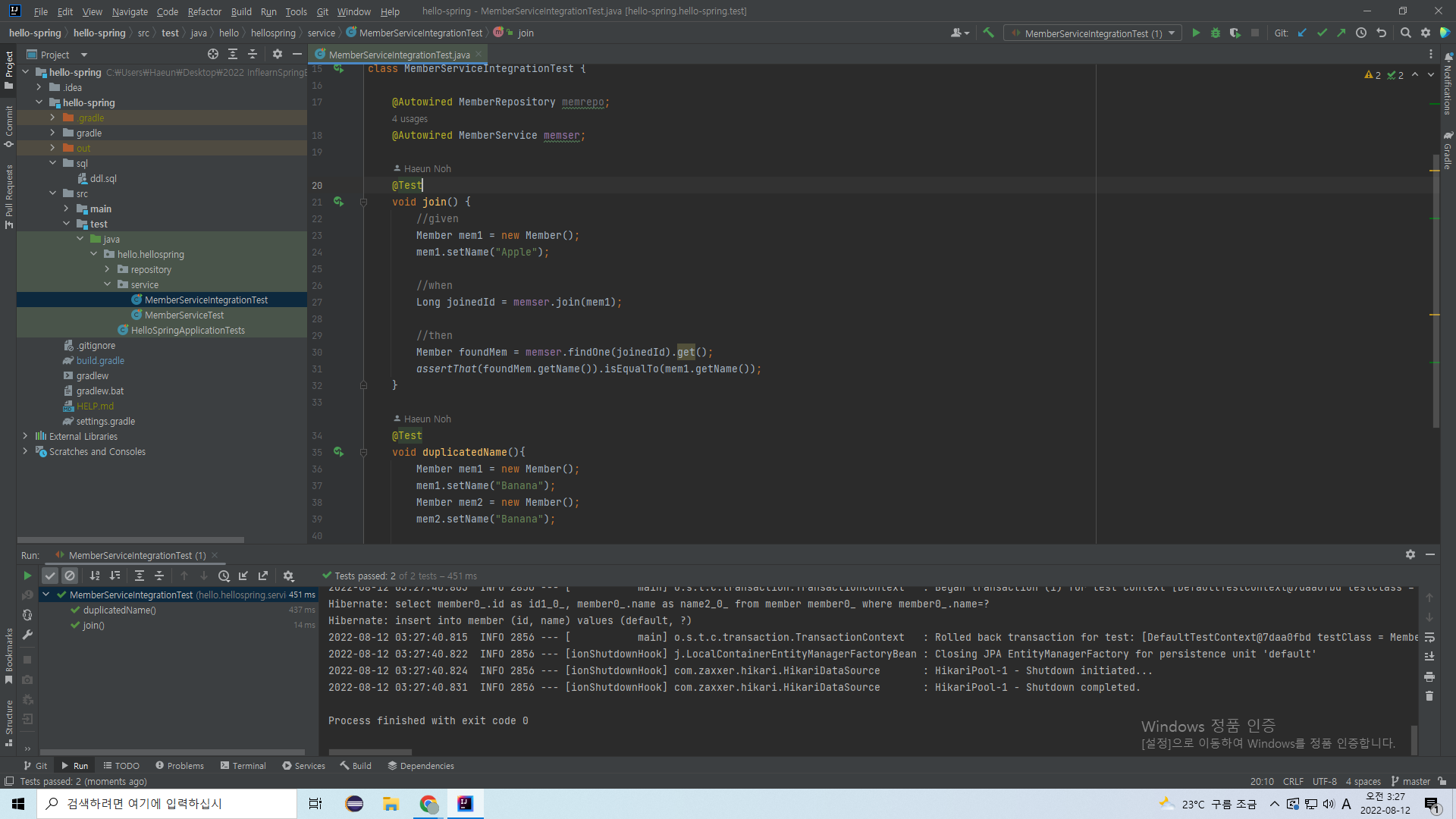
이번엔 두 개의 테스트 모두를 한 번에 돌려보았다. pass되었다.
JPA를 실무에서 사용하려면 공부를 제대로 많이 해야 한다고 한다. 인프런에도 강사님의 JPA 강의가 있다고 하니 참고하자.
'스프링 공부 > 인프런 김영한 스프링 입문 노트정리' 카테고리의 다른 글
| 7-1. AOP가 필요한 상황 (0) | 2022.08.19 |
|---|---|
| 6-6. 스프링 데이터 JPA (1) | 2022.08.01 |
| 6-4. 스프링 JdbcTemplate (0) | 2022.07.31 |
| 6-3. 스프링 통합 테스트 (0) | 2022.07.31 |
| 6-2. 순수 JDBC (0) | 2022.07.30 |